Capitolo 3. Introduzione all'uso dell'elaboratore
Questo capitolo introduttivo potrebbe fare sorridere e sembrare fuori posto in un documento che di certo non è ancora adatto a un principiante. Tuttavia, dato il titolo, si tratta di un contenitore di appunti che potrebbero essere utili a qualcuno, magari per togliere qualche preconcetto sbagliato.
3.1 Struttura
Per comprendere la struttura di un elaboratore si può immaginare il comportamento di un cuoco nella sua cucina. Il cuoco prepara delle pietanze, o piatti, che gli sono stati ordinati, basandosi sulle indicazioni delle ricette corrispondenti. Le ordinazioni vengono effettuate dai clienti che si rivolgono al cuoco perché hanno appetito.
-
L'elaboratore è la cucina;
-
il cuoco è il microprocessore o CPU;
-
l'appetito è il bisogno da soddisfare ovvero il problema da risolvere;
-
la ricetta è il programma che il microprocessore deve eseguire;
-
gli ingredienti sono l'input del programma;
-
le pietanze o i piatti sono l'output del programma.
Il cuoco, per poter lavorare, appoggia tutto quanto, ingredienti e ricetta, sul tavolo di lavoro. Su una parte del tavolo sono incise alcune istruzioni che al cuoco servono sempre; in particolare quelle che il cuoco deve eseguire ogni volta che la cucina viene aperta: pulire il tavolo, controllare tutti gli strumenti (pentole, tegami, coltelli, cucchiai ecc.) e ricevere le ordinazioni assieme alle ricette. Senza queste istruzioni di inizio, il cuoco non saprebbe nemmeno che deve accingersi a ricevere delle ordinazioni.
Come detto, il cuoco corrisponde alla CPU; il tavolo di lavoro del cuoco è la memoria centrale (o core) che si suddivide in ROM e RAM. La ROM è quella parte di memoria che non può essere alterata (nell'esempio del cuoco, si tratta delle istruzioni incise sul tavolo); la RAM è il resto della memoria che può essere alterata a piacimento dalla CPU (il resto del tavolo).
L'elaboratore è pertanto una macchina composta da una o più CPU che si avvalgono di una memoria centrale per trasformare l'input (i dati in ingresso) in output (i dati in uscita).
L'elaboratore, per poter ricevere l'input e per poter produrre all'esterno l'output, ha bisogno di dispositivi: la tastiera e il mouse sono dispositivi di solo input, lo schermo e la stampante sono in grado soltanto di emettere output. I dischi sono dispositivi che possono operare sia in input che in output.
Il cuoco si avvale di dispense per conservare derrate alimentari (pietanze completate, ingredienti, prodotti intermedi) e anche ricette. Ciò perché il tavolo di lavoro ha una dimensione limitata e non si può lasciare nulla sul tavolo quando la cucina viene chiusa, altrimenti si perde tutto quello che c'è sopra (a eccezione di ciò che vi è stato inciso).
I dischi sono paragonabili alle dispense del cuoco e servono per immagazzinare dati elaborati completamente, dati da elaborare, dati già elaborati parzialmente e i programmi.
Diverse cucine possono essere collegate tra loro in modo da poter condividere o trasmettere ricette, ingredienti,...
Le interfacce di rete e i cavi che le collegano sono il mezzo fisico per connettere insieme diversi elaboratori, allo scopo di poter condividere dati e servizi collegati a essi, ma anche per permettere la comunicazione tra gli utenti dei vari elaboratori connessi.
3.1.1 Sistema operativo
Il sistema operativo di un elaboratore è il programma più importante. È quello che viene attivato al momento dell'accensione dell'elaboratore; esso esegue gli altri programmi. Sarebbe come se il cuoco eseguisse una ricetta (il sistema operativo) che gli dà le istruzioni per poter eseguire le altre ricette.
Il sistema operativo determina quindi il comportamento dell'elaboratore. Cambiare sistema operativo in un elaboratore è come cambiare il direttore di un ufficio: a seconda della sua professionalità e delle sue doti personali, l'ufficio funzionerà in modo più o meno efficiente rispetto a prima e, pur se non cambia niente altro, per gli impiegati potrebbe tradursi in un modo di lavorare completamente nuovo.
Ci sono sicuramente affinità tra un sistema operativo e l'altro, ma questo vuol sempre dire una marea di dettagli differenti e soprattutto l'impossibilità di fare funzionare lo stesso programma su due sistemi operativi differenti, a meno che ciò sia stato previsto e voluto da chi costruisce i sistemi operativi.
3.1.2 Dispositivi
Come già accennato, i dispositivi sono qualcosa che è separato dall'elaboratore inteso come l'insieme di CPU e memoria centrale. A seconda del tipo e della loro collocazione, questi possono essere interni o periferici, ma tale tipo di distinzione è quasi scomparso nel linguaggio normale, tanto che molti chiamano ancora periferiche tutti i dispositivi. Vale la pena di distinguere fra tre tipi di dispositivi fondamentali:
-
dispositivi di memorizzazione;
-
dispositivi per l'interazione tra l'utente e l'elaboratore;
-
interfacce di rete.
I dispositivi di memorizzazione sono qualunque cosa che sia in grado di conservare dati anche dopo lo spegnimento della macchina. Il supporto di memorizzazione vero e proprio potrebbe essere parte integrante del dispositivo stesso oppure essere rimovibile.
I supporti di memorizzazione possono essere di qualunque tipo, anche se attualmente si è abituati ad avere a che fare prevalentemente con dischi (magnetici, ottici o magneto-ottici). In passato si è usato di tutto e il primo tipo di supporto di memorizzazione sono state le schede di cartoncino perforate.
Anche i dispositivi per l'interazione con l'utente possono avere qualunque forma possibile e immaginabile. Non è il caso di limitarsi all'idea che possa trattarsi solo di tastiera, schermo e mouse. Soprattutto non è il caso di supporre che un elaboratore possa avere solo uno schermo, oppure che possa avere una sola stazione di lavoro.
Le interfacce di rete sono i dispositivi che consentono la connessione tra diversi elaboratori in modo da permettere la condivisione di risorse e la comunicazione in generale. Anche in questo caso, non si può semplificare e pensare che possa trattarsi esclusivamente di schede di rete: qualunque «porta» verso l'esterno può diventare un'interfaccia di rete.
3.2 Dispositivi per l'interazione tra l'utente e la macchina
Se si lascia da parte il periodo delle schede perforate, si può dire che il primo tipo di strumento per l'interazione tra utente e macchina sia stato la telescrivente: una sorta di macchina da scrivere in grado di ricevere input dalla tastiera e di emettere output attraverso la stampante. In questo modo, l'input umano (da tastiera) era fatto di righe di testo terminate da un codice per il ritorno a capo (interruzione di riga, o newline) e nello stesso modo era composto l'output che appariva su carta.
La telescrivente era (ed è) un terminale dell'elaboratore. Ormai, la stampante della telescrivente è stata sostituita da uno schermo, che però spesso si comporta nello stesso modo: emette un flusso di testo dal basso verso l'alto, così come scorre la carta a modulo continuo attraverso una stampante. In questa situazione, la stampante ha preso un suo ruolo indipendente dal terminale originale e serve come mezzo di emissione di output finale, piuttosto che come mezzo per l'interazione.
Il terminale, composto da tastiera e schermo, o comunque da un'unità per ricevere l'input e un'altra per emettere l'output, viene visto normalmente come una cosa sola. Quando si tratta di quello principale, si parla in particolare di console.
3.2.1 Tastiera
La tastiera è una tavoletta composta da un insieme di tasti, ognuno dei quali genera un impulso particolare. È l'elaboratore che si occupa di interpretare e tradurre gli impulsi della tastiera. Questo sistema permette poi di attribuire ai tasti la funzione che si vuole.
Questo significa anche che non esiste uno standard generale di quello che una tastiera deve avere. Di solito si hanno a disposizione tasti che permettono di scrivere le lettere dell'alfabeto inglese, i simboli di punteggiatura consueti e i numeri; tutto il resto è opzionale. Tanto più opzionali sono i tasti a cui si attribuiscono solitamente funzioni particolari. Questa considerazione è importante soprattutto per chi non vuole rimanere relegato a una particolare architettura dell'elaboratore.
3.2.2 Schermo
Il terminale più semplice è composto da una tastiera e uno schermo, ma questa non è l'unica possibilità. Infatti, ci possono essere terminali con più schermi, ognuno per un diverso tipo di output.
Nel tempo, l'uso dello schermo si è evoluto, dalla semplice emissione sequenziale di output come emulazione di una stampante, a una sorta di guida di inserimento di dati attraverso modelli-tipo. Le maschere video sono questi modelli-tipo attraverso cui l'input della tastiera viene guidato da un campo all'altro. L'ultima fase dell'evoluzione degli schermi è quella grafica, nella quale si inserisce anche l'uso di un dispositivo di puntamento, solitamente il mouse, come un'estensione della tastiera.
3.2.3 Stampante
Le stampanti tradizionali sono solo in grado di emettere un flusso di testo, come avveniva con le telescriventi. Più di recente, con l'introduzione delle stampanti ad aghi, si è aggiunta la possibilità di comandare direttamente gli aghi in modo da ottenere una stampa grafica.
Ma quando la stampa diventa grafica, entrano in gioco le caratteristiche particolari della stampante. Per questo, l'ultima fase evolutiva della stampa è stata l'introduzione dei linguaggi di stampa, tra cui il più importante è stato ed è PostScript, come mezzo di definizione della stampa in modo indipendente dalle caratteristiche della stampante stessa. Così, l'output ricevuto dalle stampanti può essere costruito sempre nello stesso modo, lasciando alle stampanti l'onere di trasformarlo in base alle loro caratteristiche e capacità.
3.3 Dispositivi di memorizzazione
I dispositivi di memorizzazione sono fondamentalmente di due tipi: ad accesso sequenziale e ad accesso diretto. Nel primo caso, i dati possono essere memorizzati e riletti solo in modo sequenziale, senza la possibilità di accedere rapidamente a un punto desiderato, come con i nastri magnetici usati ancora oggi in qualità di mezzo economico per archiviare dati. Nel secondo caso, i dati vengono registrati e riletti accedendovi direttamente, come avviene con i dischi.
I dispositivi di memorizzazione ad accesso diretto, per poter gestire effettivamente questa loro caratteristica, richiedono la presenza di un sistema che organizzi lo spazio disponibile al loro interno. Questa organizzazione si chiama file system.
3.3.1 File
In prima approssimazione, il file è un'unità di informazioni che si compone in pratica di una sequenza di codici. I dispositivi di memorizzazione ad accesso diretto, muniti di file system, consentono la gestione di diversi file, mentre quelli ad accesso sequenziale permettono la gestione di un solo file su tutta la loro dimensione.
Quando il file viene visto come una semplice sequenza di codici corrispondenti a testo normale, lo si può immaginare come un testo dattiloscritto: la sequenza di caratteri viene interrotta alla fine di ogni riga da un codice invisibile che fa riprendere il testo all'inizio di una riga successiva. Questo codice di interruzione di riga, spesso identificato con il termine newline, cambia a seconda della piattaforma utilizzata.
3.3.2 File system
Il file system è il sistema che organizza i file all'interno dei dispositivi di memorizzazione ad accesso diretto. Ciò significa che tutto ciò che è contenuto in un file system è in forma di file.
Il modo più semplice per immaginare un file system è quello di un elenco di nomi di file abbinati all'indicazione della posizione in cui questi possono essere trovati. Questo sistema elementare può forse essere utile in presenza di dispositivi di memorizzazione particolarmente piccoli dal punto di vista della loro capacità.
Generalmente, si utilizzano elenchi strutturati, per cui da un elenco si viene rimandati a un altro elenco più dettagliato che può contenere l'indicazione di ciò che si cerca o il rinvio a un altro elenco ancora. Questi elenchi sono chiamati directory (o cartelle in alcuni sistemi) e sono file con questa funzione speciale.
Per questo motivo, la struttura di un file system assume quasi sempre una forma a stella (o ad albero), nella quale c'è un'origine a partire da cui si diramano tutti i file. Le diramazioni possono svilupparsi in modo più o meno esteso, a seconda delle esigenze.
Data l'esistenza di questo tipo di organizzazione, si utilizza una notazione particolare per indicare un file all'interno di un file system. Precisamente si rappresenta il percorso necessario a raggiungerlo:
-
una barra obliqua rappresenta la directory principale, altrimenti chiamata anche radice, o root;
-
un nome può rappresentare indifferentemente una directory o un file;
-
un file o una directory che discendono da una directory precedente, si indicano facendo precedere una barra obliqua.
Per esempio, /uno/due/tre rappresenta il file (o la directory) tre che discende da due, che discende da uno, che a sua volta discende dall'origine.(1)
Il tipo di file system determina le regole a cui devono sottostare i nomi dei file. Per esempio, ci possono essere situazioni in cui sono consentiti simboli speciali, come il carattere spazio, e altre in cui questo non è possibile. Nello stesso modo, la lunghezza massima dei nomi è sottoposta a un limite.
Oltre a questo, il file system permette di annotare delle informazioni accessorie che servono a qualificare i file, per esempio per poter distinguere tra directory e file contenenti dati normali.
Tradizionalmente si utilizzano due nomi convenzionali per poter fare riferimento alla directory in cui ci si trova e a quella precedente (nel senso di quella che la contiene):
-
.un punto singolo rappresenta la directory in cui ci si trova; -
..due punti in sequenza rappresentano la directory genitrice, ovvero quella che contiene la directory che si sta osservando.
3.4 Sistema operativo
Il sistema operativo è ciò che regola il funzionamento di tutto l'insieme di queste cose. Volendo schematizzare, si possono distinguere tre aspetti di questo:
3.4.1 Kernel
Il kernel è il nocciolo del sistema. Idealmente, è una sorta di astrazione nei confronti delle caratteristiche fisiche della macchina ed è il livello a cui i programmi si rivolgono per qualunque operazione. Ciò significa, per esempio, che i programmi non devono (non dovrebbero) accedere direttamente ai dispositivi fisici, ma possono utilizzare dispositivi logici definiti dal kernel. Questa è la base su cui si fonda la portabilità di un sistema operativo su piattaforme fisiche differenti.
|
Figura 3.1. Il kernel avvolge idealmente l'elaboratore e i suoi dispositivi fisici, ovvero tutto l'hardware, occupandosi di interagire con i programmi che ignorano l'elaboratore fisico.
|
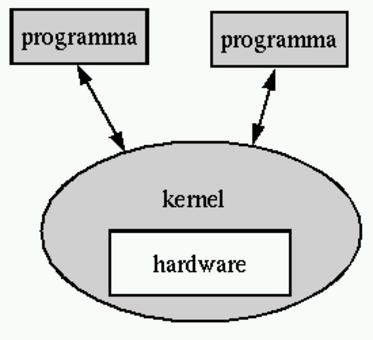
La portabilità è quindi la possibilità di trasferire dei programmi su piattaforme differenti, ciò attuato normalmente in presenza di kernel che forniscono funzionalità compatibili.
Naturalmente esistono sistemi operativi che non forniscono kernel tanto sofisticati e lasciano ai programmi l'onere di accedere direttamente alle unità fisiche dell'elaboratore. Si tratta però di sistemi di serie «B», anche se la loro nascita è derivata da necessità evidenti causate dalle limitazioni di risorse degli elaboratori per i quali venivano progettati.
3.4.2 Shell
Il kernel offre i suoi servizi e l'accesso ai dispositivi attraverso chiamate di funzione. Però, mentre i programmi accedono direttamente a questi, perché l'utente possa accedere ai servizi del sistema occorre un programma particolare che si ponga come intermediario tra l'utente (attraverso il terminale) e il kernel. Questo tipo di programma è detto shell. Come suggerisce il nome (conchiglia), si tratta di qualcosa che avvolge il kernel, come se questo fosse una perla.
|
Figura 3.2. La shell è il programma che consente all'utente di accedere al sistema. I terminali attraverso cui si interagisce con la shell sono comunque parte dell'hardware controllato dal kernel.
|

Un programma shell può essere qualunque cosa, purché in grado di permettere all'utente di avviare e possibilmente di controllare i programmi. La forma più semplice, che è anche la più vecchia, è la riga di comando presentata da un invito, o prompt. Questo sistema ha il vantaggio di poter essere utilizzato in qualunque tipo di terminale, compresa la telescrivente. Nella sua forma più evoluta, può arrivare a un sistema grafico di icone o di oggetti grafici simili, oppure ancora a un sistema di riconoscimento di comandi in forma vocale. Si tratta sempre di shell.
3.4.3 Programmi di servizio
I programmi di servizio sono un insieme di piccole applicazioni utili per la gestione del sistema. Teoricamente, tutte le funzionalità amministrative per la gestione del sistema potrebbero essere incorporate in una shell; in pratica, di solito questo non si fa. Dal momento che le shell tradizionali incorporano alcuni comandi di uso frequente, spesso si perde la cognizione della differenza che c'è tra le funzionalità fornite dalla shell e i programmi di servizio.
3.5 Programmi applicativi
L'elaboratore non può essere una macchina fine a se stessa. Deve servire a qualcosa, al limite a giocare. È importante ricordare che tutto nasce da un bisogno da soddisfare. I programmi applicativi sono quelli che (finalmente) servono a soddisfare i bisogni e quindi rappresentano l'unica motivazione per l'esistenza degli elaboratori.
3.6 Riferimenti
-
Eric S. Raymond, The Unix and Internet Fundamentals HOWTO
<http://www.linux.org/docs/ldp/howto/HOWTO-INDEX/howtos.html>
daniele @ swlibero.org1) Il tipo di barra obliqua che si utilizza dipende dal sistema operativo. La barra obliqua normale corrisponde al sistema tradizionale.