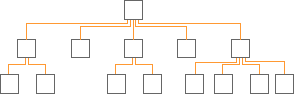
A B* tree is a search tree that may have more than two references per node.The figure below shows a B* tree with up to five children per node.
A B* tree
A B* tree combines the advantages of binary search and sequential access upon the same set of keys. B* trees are based on two simple ideas:
A B* tree implementation variant is suitable when you have many large elements that are accessed by key. Because keys and their data are separated, the keys in the tree structure are used for a quick search and the pointers are used for quick access to the data.
In contrast to a B* tree, keys and data in an AVL tree are both stored in the nodes. This means that searching through elements could cause page faults if the elements are large, because the various keys may be spread across several pages along with the data they refer to.
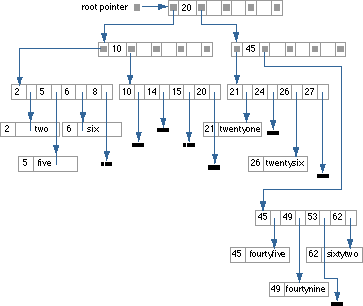
In the figure below, the B* tree has an order of 5 (which means that each internal node has a maximum of five references). The data is stored only in the leaves. A leaf block is built to hold one element. A leaf block may be larger than one page. The B* tree implementation uses the keys in the nodes for quick access to a required page (leaf), or it uses the keys for a quick sequential access to all pages, and hence to all elements.
B* Tree Implementation Variant
![]()
Introduction to the
Collection Classes
Collection Class
Hierarchy
Overall
Implementation Structure
Flat Collections
Trees
AVL Tree Diluted Table
Hash Table
List
Table
![]()
Class Template
Naming Conventions
Possible
Implementation Paths
Choosing One
of the Provided Implementation Variants
Replacing the
Default Implementation
Taking Advantage
of the Abstract Class Hierarchy
Instantiating
the Collection Classes
