The primary class in the Unicode support classes is IUnicode, which lets you determine a character's script and character properties. The Unicode support classes also provide a mechanism for referencing specific Unicode character values by name instead of by codepoint values.
The class library also provides a set of classes that contain enumerated names for each Unicode character value. These classes correspond to groups of characters based on script or functions: ULatin, UGreek, UDingbats, UMathematicalOperators, and so on. Use the names enumerated in these classes to reference specific Unicode character values.
The Unicode character set provides full character coverage for the major scripts listed below, as well as for punctuation, symbols, and control characters. The character set for each script is independent--even if a character appears in multiple scripts, it has a separate code within each script. For example, the character A has one code for the Roman alphabet, another code for the Greek alphabet, and yet another code for the Cyrillic alphabet. However, because more than one language may use a given alphabet, the character A is represented by the same code for English, French, and, in fact, all languages that use the Roman alphabet.
| Arabic | Georgian | Hangul | Malayam | Thai |
| Armenian | Greek | Hebrew | Oriya | Zhuyinfuhao |
| Bengali | Gujarati | Kana | Roman | |
| Cyrillic | Gurmukhi | Kannada | Tamil | |
| Devanagari | Han | Lao | Telugu |
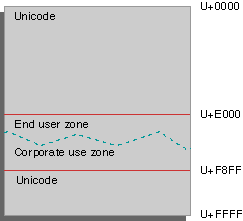
The Unicode standard sets aside a range of characters--from U+E000 to U+F8FF--for private use for: